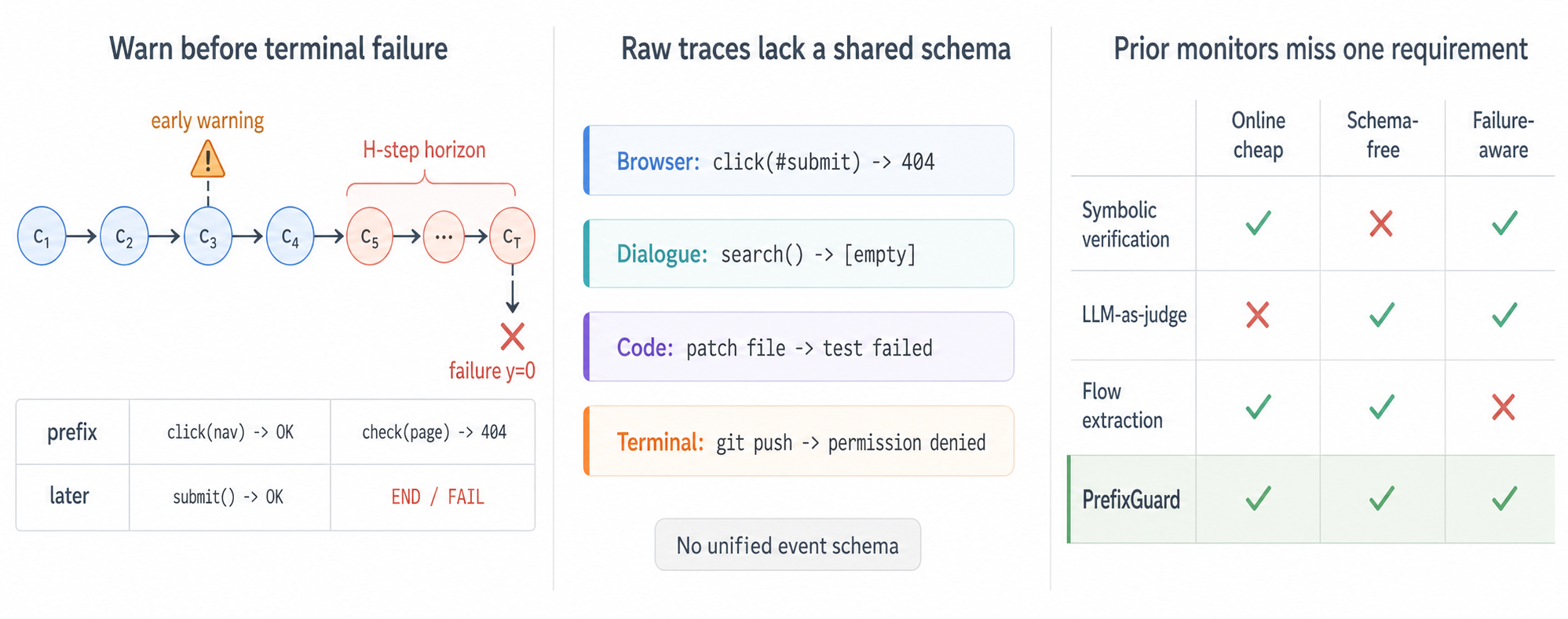
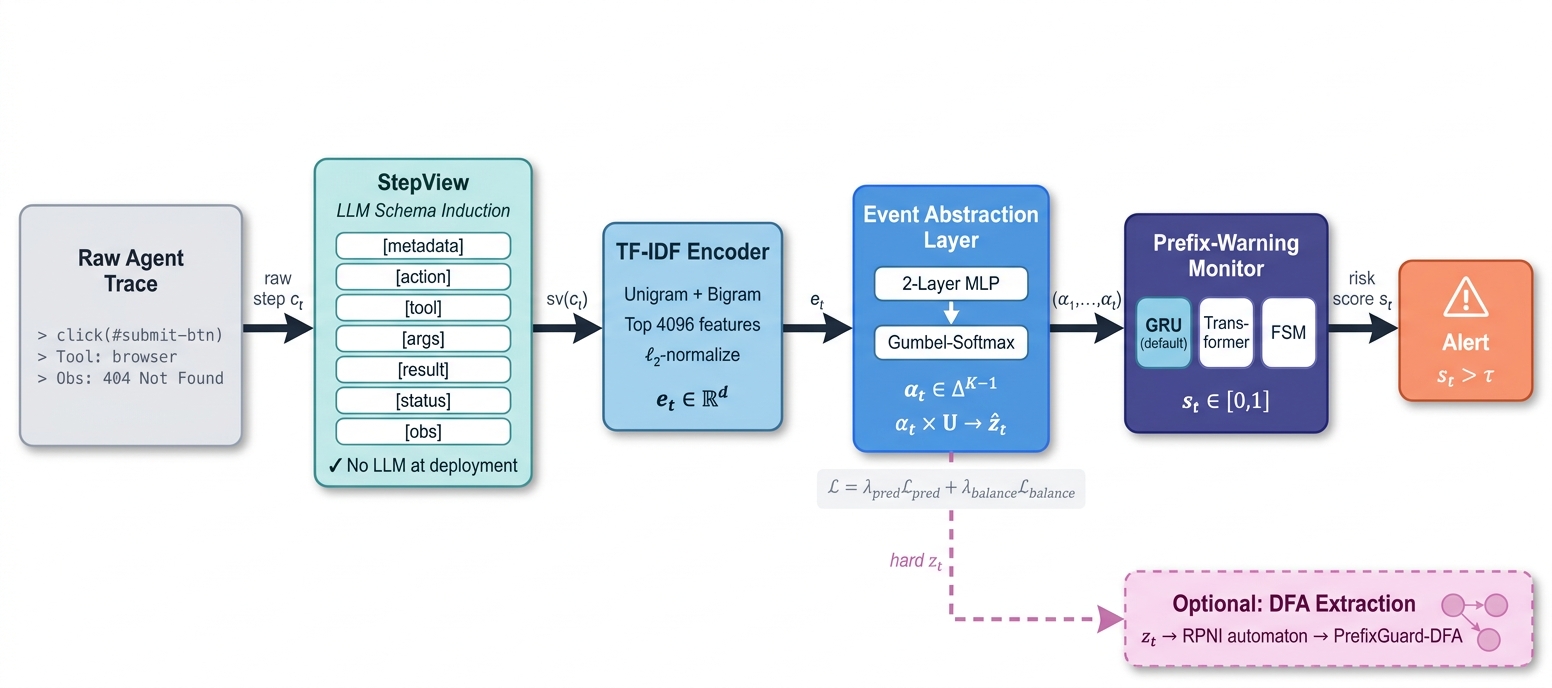
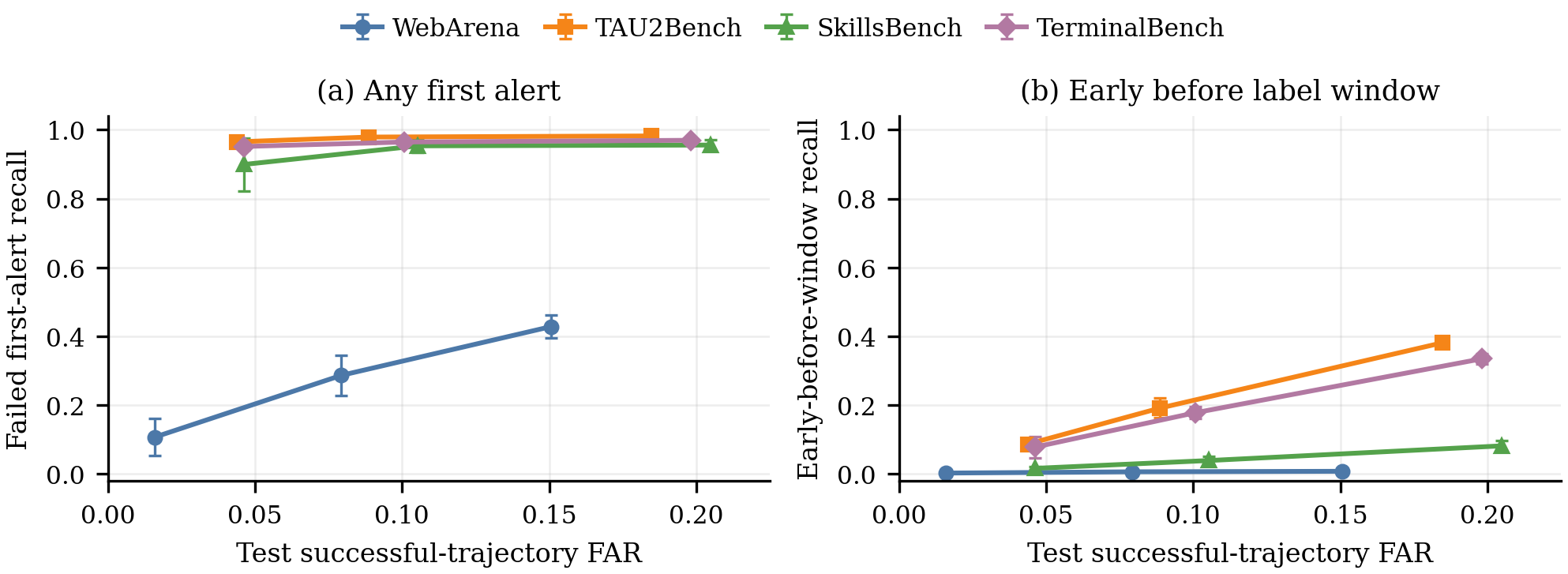
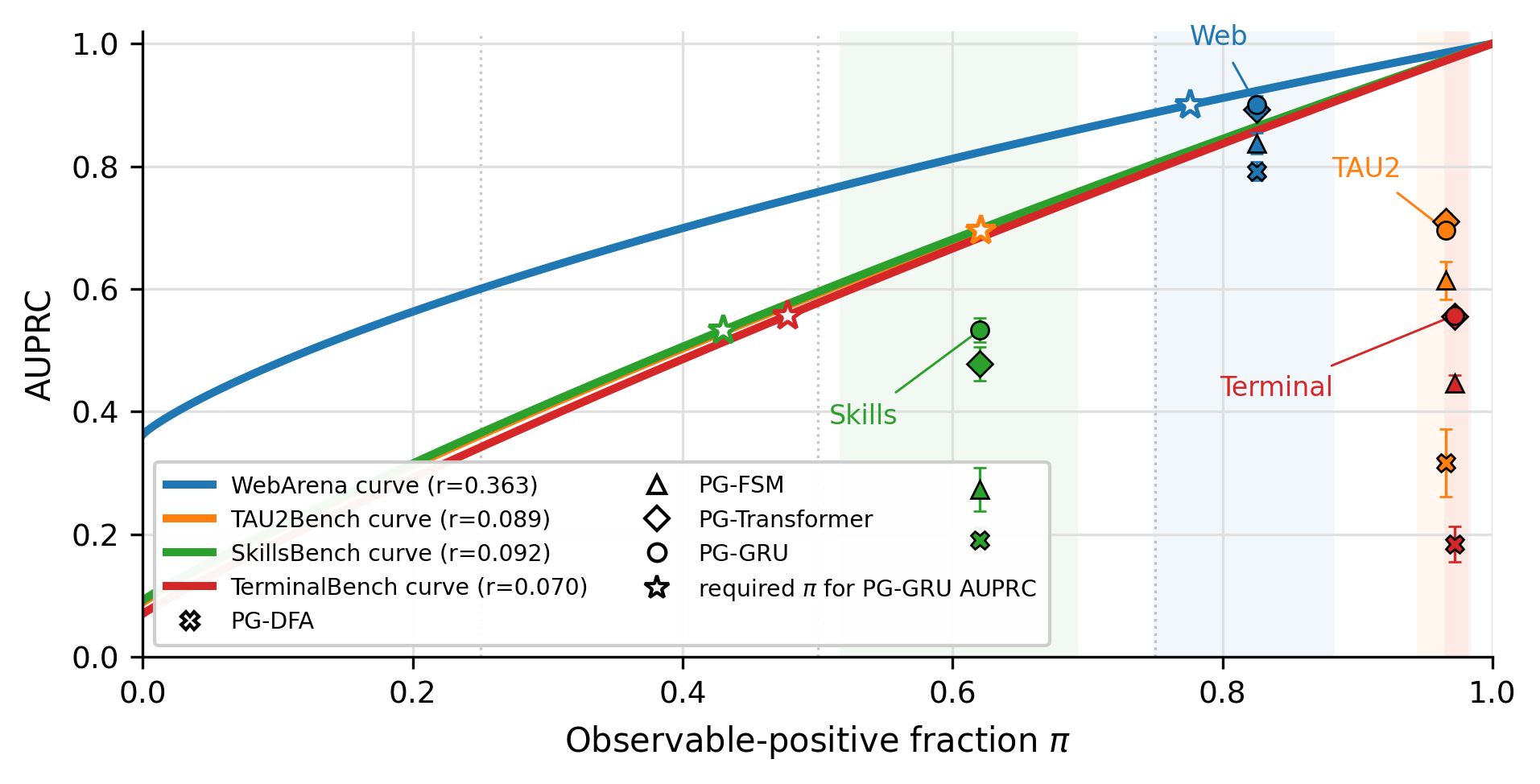
PrefixGuard: From Large Language Model Agent Traces to Online Failure-Warning Monitors
0.900
WebArena AUPRC
0.710
τ2-Bench AUPRC
+0.137
Average gain vs. raw-text controls